
Text Mining
Several projects I've worked on in have involved text mining. The aim of text mining strategies varies from project to project but generally speaking it is used to quantify unstructured content for efficient analysis and retrieval of text documents. This project post will provide a high-level overview of how text mining has been employed in projects I've worked on, explain core concepts behind methods employed and outline ideas for future project development.
Process & Methodology
Within a typical design-research project, the decision to employ text mining tools and strategies generally comes as a result of the volume of data that needs to be processed and analyzed. In these instances, text mining has been an effective strategy for automating laborious and time intensive research tasks. For projects I have developed text mining tools, the tools typically are designed for the purpose of filtering out irrelevant information and identifying where information of potentially significant value to the project are. An information targeting tool in a sense.
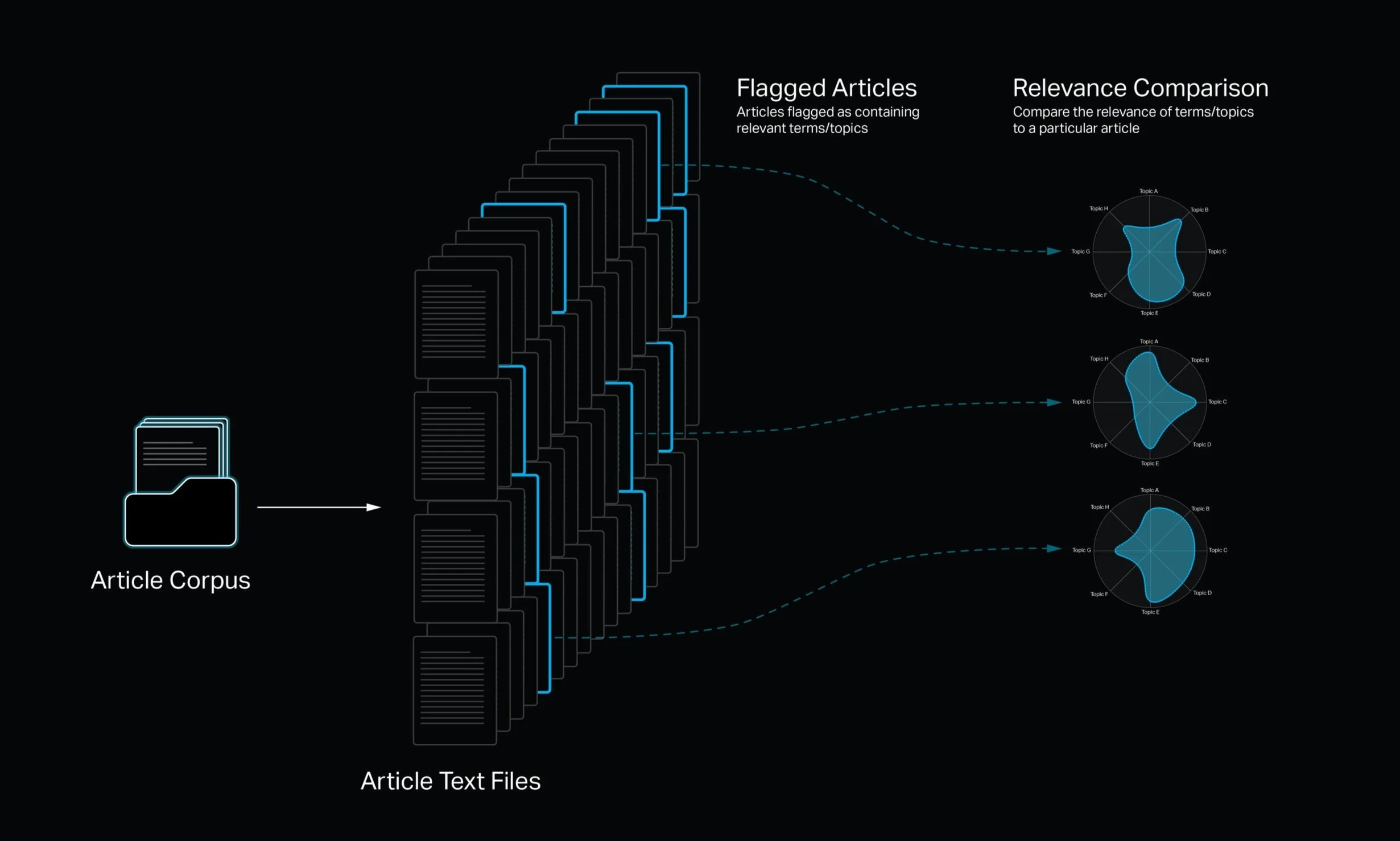
For example, let’s say we want to identify relevant and trending topics across a corpus of 1000 articles. We could read each article in that corpus and manually flag interesting topics, but that process is time-consuming and your brain will undoubtably become fatigued and you will probably miss relevant information. Much of your time may end up being spend reading articles with no or minimally relevant information, so it's simply not an efficient use of time.
Text timing algorithms can help streamline this process by reading through each of the documents and conducting natural language processing and analysis methods that ultimately let us flag articles with relevant information. Additionally, we can map patterns in the way terms are used across the corpus of articles to show trends in the frequency and/or relevance of terms and topics for a high-level trend analysis.
Term Relevance

We can measure the relevance of a term across the entire corpus of articles and the relevance of the term to each individual article with a term frequency - inverse document frequency analysis, otherwise referred to as TFIDF. A TFIDF analysis allows us to numerically rank terms with based on the relevance of the term so we can easily filter out terms with low relevance and focus on terms with high relevance. TFIDF essentially says, if a term appears in many articles, then the term probably is not as relevant to those articles because it is less unique. Inversely, if a term appears in only a few articles, that terms is probably more relevant to the articles it appears in. With that in mind, the frequency of the term within each article it appears in also plays a role in how relevant it is.
Execution
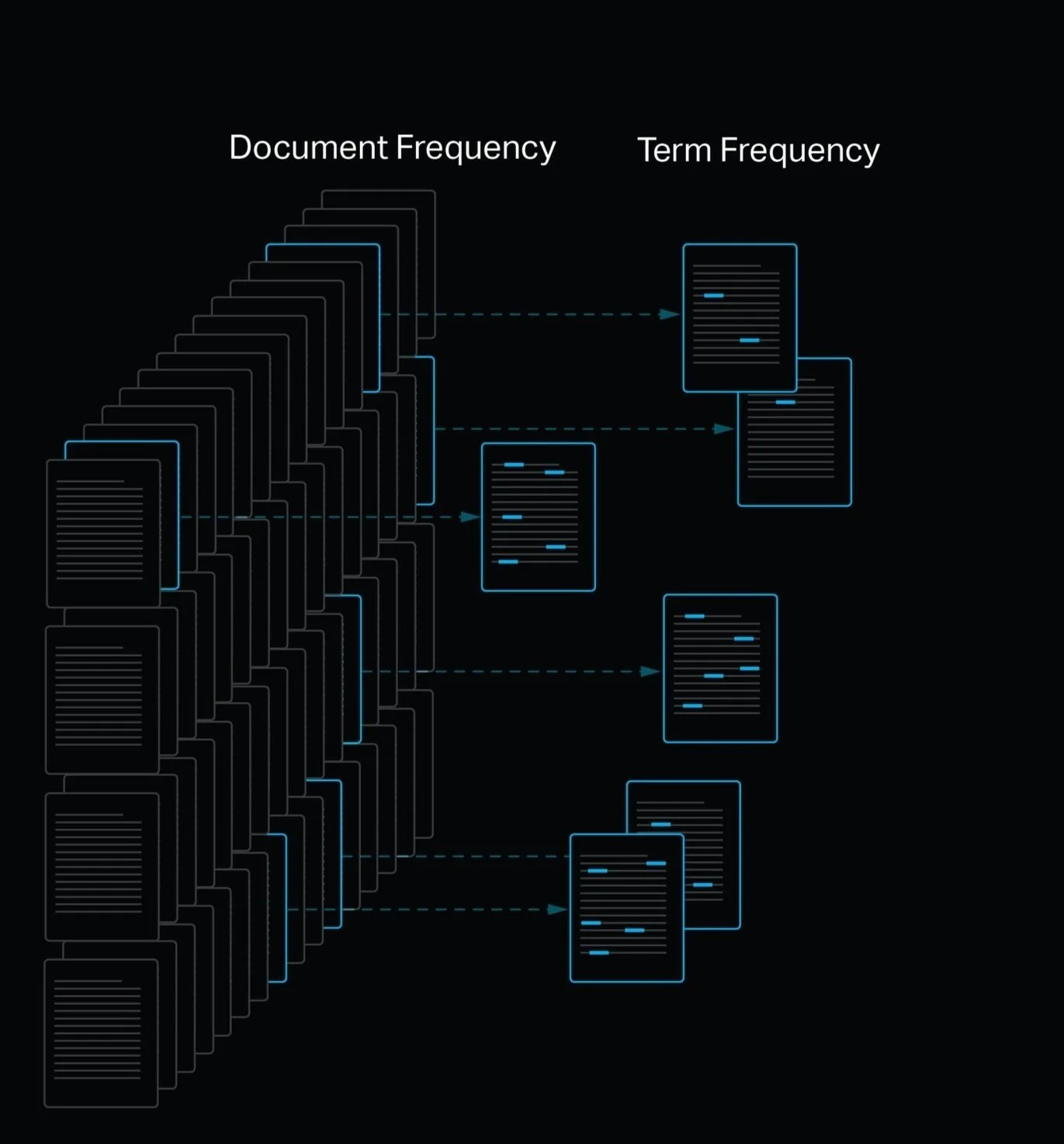
The text mining tools overviewed in this post are written in Python with dependencies on libraries including Numpy and Regex for array manipulation and text parsing respectively. Conceptually, I tried to take an object oriented approach by treating documents and unique terms as an instances of a class objects. For term objects, the attributes contain a dictionary where the documents and the frequency of the term in each document are logged and later used for the TFIDF analysis. Tracking each document the term appears in allows us to easily see exactly which documents a term can be found in and the relevance of that term to the document.

Process Overview
This diagram is intended to provide a high level overview of how raw text is parsed, filtered and structured.
Term Objects

For now, my code creates an instance of a class object called "TermObject" each time a new unique term is found. The initialized instance of the TermObject consists of the following attributes.
Term ID: A numeric ID used for the term. The numeric value is simply the count of existing TermObject instances +1
Stem Text: The stemmed version of the term
Document Dictionary: A dictionary used to track the document ids where the term appears and the number of times the term appears in the document
Document Frequency: An integer derived from the number of items in the Document Dictionary
IDF: Result of the inverse document frequency calculation
TF-IDF: Result of the term frequency - inverse document frequency calculation
TF-IDF Normalized: The TF-IDF value scaled between zero and one
Flag: A boolean which indicates if the TF-IDF value is greater than a given minimum threshold.
Applications
As part of a research effort to gain a better understanding of sustainable design in the architecture, engineering and construction industries, web-scraping and text mining were used to collect data, identify relevant topics and map the interconnection of topics as they relate to one another. This example shown was from an early proof of concept to illustrate the capabilities of custom scraping and text mining tools written for the research effort. For this proof of concept, the idea was to scrape Wikipedia articles related to sustainable design, run text mining analysis on the scraped text and visualize the results as a series of brush style word maps.
Process

The Python scraper is given a Wikipedia article to start at. The scraper uses Beautiful Soup to extract and parse HTML from the article and searches for specific elements to extract the article metadata, text and links to referenced articles and sources. The URL links to referenced articles are stored in a list and are cycled through with a While loop to recursively scrape the referenced articles up to a given limit. The limit in this case tells the scraper how many articles deep to go. Before moving onto the next article, the extracted content is written to a local JSON file which stores the scraped content as a nested dictionary.

As noted above, the Python scraper will recursively move from one article to another while within given limit. As the scraper moves from one article to another, it tracks its depth from the root article. Depth in this case, refers to how deep of a rabbit hole the scraper is digging itself into. For example, if you start off at article "A" and article "A" has links to articles "B","C" and "D", moving to any one of those articles will put the scraper at a depth of 1. Lets say we move to article "B" and follow a link to article "E". Now we are at a depth of 2 because if we were to backtrack to article "A" we would go through article "E" and article "V". The given depth limit tells the scraper when to stop following nested links as to avoid moving too far away from the root article where content likely looses relevance.

After the scraping process was completed, the text from the scraped articles was analyzed to calculate the relevance of terms with TFIDF and terms with particularly high relevance were put in a keyword dictionary. The next step was to visualize relationships between terms. For each term in the keyword dictionary to produce a series of term-relationship maps where terms with high TFIDF scores that appear in the same articles as the selected keyword are mapped to the keyword (Fig 1).

Interactive Visualizations
This video is from a quick prototype where documents are rendered as 3D objects using Three.js. The xyz coordinates of the documents are derived from the document’s vectorized text and the object’s color is based on the topic category of the document. The idea was to think of the documents as a point cloud where documents of similar text cluster closer together. I’m planning to revisit this idea in the near future.